NEODAAS offers support for optimising Earth Observation applications. Our experts can work with you to identify the best approach to improve the efficiency of your software, reducing processing time and energy usage where possible. Portable solutions can be developed to ensure the software can be run on your chosen infrastructure. Training materials can also be made available to enable you to maintain and develop the optimised code and apply the new techniques to future software.
We are able to offer support in the following areas:
Code optimisation on CPUs
Specialising in Python development, we use modern libraries and software best practices to improve the efficiency of code running on the CPU. We can review existing code and provide alternative solutions that use less resource.
Porting of code to GPUs
We can help port code that is well suited to acceleration using a Graphics Processing Unit (GPU) and can provide access to the NEODAAS MAGEO system (Massive GPU Cluster for Earth Observation) to run suitable software. Using GPU libraries and parallelizing code, software can be adapted to make use of the many cores available on MAGEO, which can significantly reduce processing time.

Replacement of code with an AI approach
NEODAAS AI experts can help to identify when an AI approach may be used to replace existing software, for example by running a model and then creating a net to replace outputs.
Getting in touch
If you would like support with optimising an application, please get in touch with NEODAAS –helpdesk@neodaas.ac.uk – to discuss your requirements.
Case studies
Check out some of our case studies below that highlight the success in optimising applications using a range of approaches.
- Improving the performance of National Centre for Earth Observation (NCEO) code using GPUs – A small study was carried out with NCEO, investigating the advantages of different tools designed for running code on GPUs. Examples of Python code were obtained from NCEO scientists, and the applications were ported to GPUs on the NEODAAS MAGEO system using various libraries (e.g., Numba). Comparisons were made between the time taken to run the application on the original CPU and the MAGEO CPU and GPU. The modified code ran between 30 and 1800 times faster using a GPU. The report summarising the project is available to view via PML Publishing [https://doi.org/10.17031/wtr8-2k34]. The example code used in the project can be found here.
- Using K-fold cross validation to speed up processing – In a recent (Dec 2022) request, NEODAAS estimated that running user-supplied code would take 48 hours using all 40 GPUs available on the MAGEO cluster. Following discussions with the user, we replaced their method with a K-fold cross-validation approach. The updated process took less than 1 hour to run using 24 GPUs on MAGEO: i.e., requiring only ~1% of the processing and, hence, ~1% of the energy consumption/carbon production.
- Efficient use of resources for cataloguing over one million ship tracks – This study with the University of Oxford and Imperial College, London used state-of-the-art satellite machine-learning to automate ship track detection. We catalogued more than one million ship tracks over a 20-year period to provide a global climatology. To efficiently apply the model to 200TB of data, ensuring we could get data to the MAGEO GPUs fast enough was important so we batched images using TensorFlow datasets to optimise this. For generating polygons from the ship tracks we utilised the NVIDIA RAPIDS framework to run on the GPUs. This was 10 times faster than just using the CPU. By optimising the output format we were able to reduce the size of the final dataset from 50TB to 10TB before sending to CEDA for archiving. Read more here:
#NewPaper ‘Shipping regulations lead to large reduction in cloud perturbations’ published in @PNASNews establishes the first clear evidence of a global cloud response to changes in environmental regulations https://t.co/f5urgaKpVP @UniofOxford @imperialcollege @NEODAAS pic.twitter.com/eL2ckdjlhl
– Plymouth Marine Lab (@PlymouthMarine) October 25, 2022
- UK EOCIS processing chain optimization- As part of the UK Earth Observation Climate Information Service (EOCIS) PML scientists have re-developed an OLCI Level 1 to Level 3 processing chain to make it more efficient. By using new libraries and approaches, the processing chain has not only been made more portable and easier to maintain, but also runs approximately 3 times faster and uses an estimated 50% less power.
- Replicating a computationally-expensive marine biogeochemistry model with machine learning emulator to reduce computational cost – A PML funded research project was carried out to build machine learning (ML) emulators of the highly-complex European Regional Seas Ecosystem Model (ERSEM, developed at PML) to predict oxygen at different locations on the North-West European Shelf (NWES). The ML emulators used as inputs atmospheric forcing data and riverine discharge, with sea surface temperature (SST) and chlorophyll-a satellite observations. The purpose of the ML models was to replicate the ERSEM behaviour within the operational system for the NWES run at the UK Met Office, where the model is re-initialized with the available satellite SST and chlorophyll data (using data assimilation) and forced by the atmospheric and riverine discharge data. The ML emulators were shown to be skilled in two end-user applications: to predict oxygen at L4 for observational science applications and to predict oxygen in German Bight (a hypoxic area) for aquaculture industry. The computational cost of the ML emulators was several orders of magnitude smaller than running the operational system. You can find out more in the paper here: https://www.frontiersin.org/articles/10.3389/fmars.2023.1058837/full or watch the video below:
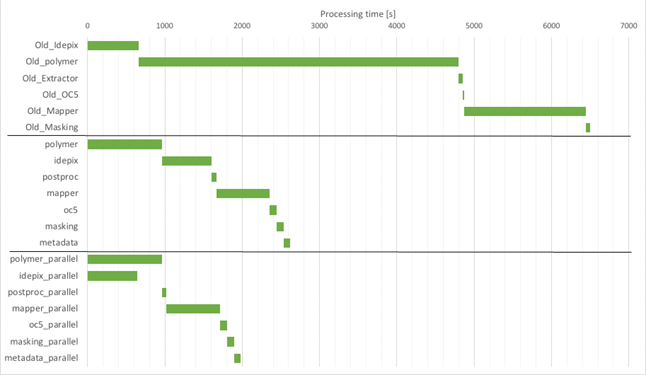
- Efficiency improvements for global lake water quality processing chains – PML has an active community of scientists working on improving satellite-derived measurements of inland water quality; these improvements are fed into Calimnos, the in-house satellite data processing software used by ESA CCI Lakes and the Copernicus Land Monitoring Service. PML recently received funding from ESA as part of the Lakes Climate Change Initiative project to improve the efficiency of Calimnos for large-scale reprocessing. Firstly, the chain was thoroughly benchmarked and bottlenecks identified. Slow external libraries were identified and replaced. Algorithm code was rewritten for speed and additional vectorisation was carried out. The order of processing was reorganised in places to reduce read/write operations. The improvements led to increased efficiency in the order of 50% of the original time.
Training Materials
We continue to develop training materials to support with applying various optimisation techniques. You’ll find some examples to help you get started below.
- Porting Python code to GPUs – A Jupyter notebook provides an introduction to using Numba and CuPy to optimize code performance.